readxl::read_excel() brings data from a rectangle of
cells into R as a data frame or, more specifically, a tibble.
The extent of the data rectangle can be determined in various ways:
-
Discovered: By default,
read_excel()uses the smallest rectangle that contains the non-empty cells. It “shrink wraps” the data. -
Bounded: The
skipandn_maxarguments constrainread_excel()’s discovery process with respect to rows. At leastskipspreadsheet rows will be skipped or ignored and at mostn_maxspreadsheet rows will be considered as data. Compared to the default of discovery, these arguments can only lead to making the output tibble smaller. -
Set: The
rangeargument is taken literally, even if that means you will have leading or trailing rows or columns filled withNA. If you ask forrange = "A1:D4", you are guaranteed to get a tibble with 4 columns (A through D) and either 3 rows (col_names = TRUE, default) or 4 rows (col_names = FALSE). -
Mixed: In typical use,
read_excel()’s geometry arguments often imply that certain limits are discovered while others are bounded or set. This will be more clear in the concrete examples below.
For now, here are a few ways read_excel() can look when
you take control of the geometry:
read_excel("yo.xlsx", skip = 5)
read_excel("yo.xlsx", n_max = 100)
read_excel("yo.xlsx", skip = 5, n_max = 100)
read_excel("yo.xlsx", range = "C1:E7")
read_excel("yo.xlsx", range = cell_rows(6:23))
read_excel("yo.xlsx", range = cell_cols("B:D"))
read_excel("yo.xlsx", range = anchored("C4", dim = c(3, 2)))Little known Excel facts
readxl’s behavior and interface may be easier to understand if you understand this about Excel:
Cells you can see don’t necessarily exist. Cells that look blank aren’t necessarily so.
Among lots of other information, Excel files obviously must contain information on each cell. Let’s use the word “item” to denote one cell’s-worth of info.
Just because you see a cell on the screen in Excel, that doesn’t mean there’s a corresponding item on file. Why? Because Excel presents a huge gridded canvas for you to write on. Until you actually populate a cell, though, it doesn’t really exist.
The stream of cell items describes the existing cells, going from upper left to lower right, travelling by row. Blank cells simply do not exist in it.
Ah, but what is a blank cell? Some cells appear blank to the naked eye but are not considered so by Excel and, indeed, are represented by a cell item. This happens when a cell has no content but does have an associated format. This format could have been applied directly to a single cell or, more often, indirectly via formatting applied to an entire row or column. Once a human has spent some quality time with a spreadsheet, many seemingly empty cells will bear a format and will thus have an associated cell item.
Implications for readxl
readxl only reads cell items that have content. It ignores cell items that exist strictly to convey formatting.
The tibble returned by readxl will often cover cells that are empty
in the spreadsheet, filled with NA. But only because there
was some other reason for the associated row or column to exist: actual
data or user-specified geometry.
skip and n_max
skip and n_max are the “entry-level”
solution for controlling the data rectangle. They work only in the row
direction. Column-wise, you’re letting readxl discover which columns are
populated.
If you specify range (covered below), skip
and n_max are ignored.
skip
The skip argument tells read_excel() to
start looking for populated cells after skipping at least
skip rows. If the new start point begins with 1 or more
empty rows, read_excel() will skip even more before it
starts reading from the sheet.
Here’s a screen shot of the geometry.xlsx example sheet
that ships with readxl, accessible via
readxl_example("geometry.xlsx").
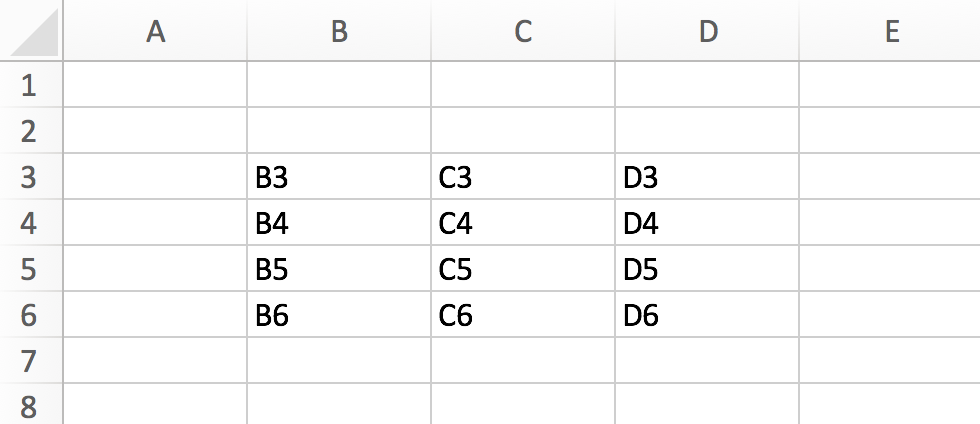
By default, read_excel() just discovers the data
rectangle:
read_excel(readxl_example("geometry.xlsx"))
#> # A tibble: 3 × 3
#> B3 C3 D3
#> <chr> <chr> <chr>
#> 1 B4 C4 D4
#> 2 B5 C5 D5
#> 3 B6 C6 D6If you explicitly skip one row, note that read_excel()
still skips row 2, which is also empty, leading to the same result as
before:
read_excel(readxl_example("geometry.xlsx"), skip = 1)
#> # A tibble: 3 × 3
#> B3 C3 D3
#> <chr> <chr> <chr>
#> 1 B4 C4 D4
#> 2 B5 C5 D5
#> 3 B6 C6 D6You can also use skip to skip over populated cells. In
real life, this is a mighty weapon against the explanatory text that
people like to include at the top of spreadsheets.
read_excel(readxl_example("geometry.xlsx"), skip = 3)
#> # A tibble: 2 × 3
#> B4 C4 D4
#> <chr> <chr> <chr>
#> 1 B5 C5 D5
#> 2 B6 C6 D6Summary: skip tells read_excel() to skip
at least this many spreadsheet rows before reading
anything.
n_max
The n_max argument tells read_excel() to
read at most n_max rows, once it has found the data
rectangle. Note that n_max is specifically about the
data. You still use col_names to express whether the
first spreadsheet row should be used to create column names (default is
TRUE).
n_max = 2 causes us to ignore the last data row – the
3rd one – in geometry.xlsx.
read_excel(readxl_example("geometry.xlsx"), n_max = 2)
#> # A tibble: 2 × 3
#> B3 C3 D3
#> <chr> <chr> <chr>
#> 1 B4 C4 D4
#> 2 B5 C5 D5n_max is an upper bound. It will never cause empty rows
to be included in the tibble. Note how we get 3 data rows here, even
though n_max is much greater.
read_excel(readxl_example("geometry.xlsx"), n_max = 1000)
#> # A tibble: 3 × 3
#> B3 C3 D3
#> <chr> <chr> <chr>
#> 1 B4 C4 D4
#> 2 B5 C5 D5
#> 3 B6 C6 D6
range
The range argument is the most flexible way to control
geometry and is powered by the cellranger
package.
One huge difference from skip and n_max is
that range is taken literally! Even if it means the
returned tibble will have entire rows or columns consisting of
NA.
You can describe cell limits in a variety of ways:
Excel-style range: Specify a fixed rectangle with
range = "A1:D4" or range = "R1C1:R4C4". You
can even prepend the worksheet name like so:
range = "foofy!A1:D4" and it will be passed along to the
sheet argument.
The deaths.xlsx example sheet features junk rows both
before and after the data rectangle. The payoff for specifying the data
rectangle precisely is that we get the data frame we want, with correct
guesses for the column types.
read_excel(readxl_example("deaths.xlsx"), range = "arts!A5:F15")
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> # ℹ 6 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>We repeat the screenshot of geometry.xlsx as a visual
reference.
Going back to geometry.xlsx, here we specify a rectangle
that only partially overlaps the data. Note the use of default column
names, because the first row of cells is empty, and the leading column
of NAs.
read_excel(readxl_example("geometry.xlsx"), range = "A2:C4")
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
#> • `` -> `...3`
#> # A tibble: 2 × 3
#> ...1 ...2 ...3
#> <lgl> <chr> <chr>
#> 1 NA B3 C3
#> 2 NA B4 C4Specific range of rows or columns: Set exact limits on just the rows or just the columns and allow the limits in the other direction to be discovered. Example calls:
## rows only
read_excel(..., range = cell_rows(1:10))
## is equivalent to
read_excel(..., range = cell_rows(c(1, 10)))
## columns only
read_excel(..., range = cell_cols(1:26))
## is equivalent to all of these
read_excel(..., range = cell_cols(c(1, 26)))
read_excel(..., range = cell_cols("A:Z"))
read_excel(..., range = cell_cols(LETTERS))
read_excel(..., range = cell_cols(c("A", "Z"))We use geometry.xlsx to demonstrate setting hard limits
on the rows, running past the data, while allowing column limits to
discovered. Note the trailing rows of NA.
read_excel(readxl_example("geometry.xlsx"), range = cell_rows(4:8))
#> # A tibble: 4 × 3
#> B4 C4 D4
#> <chr> <chr> <chr>
#> 1 B5 C5 D5
#> 2 B6 C6 D6
#> 3 NA NA NA
#> 4 NA NA NAAnchored rectangle: Helper functions
anchored() and cell_limits() let you specify
limits via the corner(s) of the rectangle.
Here we get a 3 by 4 rectangle with cell C5 as the upper left corner:
read_excel(
readxl_example("geometry.xlsx"),
col_names = paste("var", 1:4, sep = "_"),
range = anchored("C5", c(3, 4))
)
#> # A tibble: 3 × 4
#> var_1 var_2 var_3 var_4
#> <chr> <chr> <lgl> <lgl>
#> 1 C5 D5 NA NA
#> 2 C6 D6 NA NA
#> 3 NA NA NA NAHere we set C5 as the upper left corner and allow the other limits to be discovered:
read_excel(
readxl_example("geometry.xlsx"),
col_names = FALSE,
range = cell_limits(c(5, 3), c(NA, NA))
)
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
#> # A tibble: 2 × 2
#> ...1 ...2
#> <chr> <chr>
#> 1 C5 D5
#> 2 C6 D6