readxl::read_excel() will guess column types, by
default, or you can provide them explicitly via the
col_types argument. The col_types argument is
more flexible than you might think; you can mix actual types in with
"skip" and "guess" and a single type will be
recycled to the necessary length.
Here are different ways this might look:
read_excel("yo.xlsx")
read_excel("yo.xlsx", col_types = "numeric")
read_excel("yo.xlsx", col_types = c("date", "skip", "guess", "numeric"))Type guessing
If you use other packages in the tidyverse, you are probably familiar with readr, which reads data from flat files. Like readxl, readr also provides column type guessing, but readr and readxl are very different under the hood.
- readr guesses column type based on the data.
- readxl guesses column type based on Excel cell types.
Each cell in an Excel spreadsheet has its own type. For all intents and purposes, they are:
empty < boolean < numeric < text
with the wrinkle that datetimes are a very special flavor of numeric.
A cell of any particular type can always be represented as one of any
higher type and, possibly, as one of lower type. When guessing,
read_excel() keeps a running “maximum” on the cell types it
has seen in any given column. Once it has visited guess_max
rows or run out of data, this is the guessed type for that column. There
is a strong current towards “text”, the column type of last resort.
Here’s an example of column guessing with deaths.xlsx
which ships with readxl.
read_excel(readxl_example("deaths.xlsx"), range = cell_rows(5:15))
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> # ℹ 6 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>Excel types, R types, col_types
Here’s how the Excel cell/column types are translated into R types
and how to force the type explicitly in col_types:
| How it is in Excel | How it will be in R | How to request in col_types
|
|---|---|---|
| anything | non-existent | "skip" |
| empty |
logical, but all NA
|
you cannot request this |
| boolean | logical |
"logical" |
| numeric | numeric |
"numeric" |
| datetime | POSIXct |
"date" |
| text | character |
"text" |
| anything | list |
"list" |
Some explanation about the weird cases in the first two rows:
- If a column falls in your data rectangle, but you do not want an
associated variable in the output, specify the column type
"skip". Internally, these cells may be visited in order to learn their location, but they are not loaded and their data is never read. - You cannot request that a column be included but filled with
NAs. Such a column can arise naturally, if all the cells are empty, or you can skip a column (see previous point).
Example of skipping and guessing:
read_excel(
readxl_example("deaths.xlsx"),
range = cell_rows(5:15),
col_types = c("guess", "skip", "guess", "skip", "skip", "skip")
)
#> # A tibble: 10 × 2
#> Name Age
#> <chr> <dbl>
#> 1 David Bowie 69
#> 2 Carrie Fisher 60
#> 3 Chuck Berry 90
#> 4 Bill Paxton 61
#> # ℹ 6 more rowsMore about the "list" column type in the last row:
- This will create a list-column in the output, each component of which is a length one atomic vector. The type of these vectors is determined using the logic described above. This can be useful if data of truly disparate type is arranged in a column.
We demonstrate the "list" column type using the
clippy.xlsx sheet that ship with Excel. Its second column
holds information about Clippy that would be really hard to store with
just one type.
(clippy <-
read_excel(readxl_example("clippy.xlsx"), col_types = c("text", "list")))
#> # A tibble: 4 × 2
#> name value
#> <chr> <list>
#> 1 Name <chr [1]>
#> 2 Species <chr [1]>
#> 3 Approx date of death <dttm [1]>
#> 4 Weight in grams <dbl [1]>
tibble::deframe(clippy)
#> $Name
#> [1] "Clippy"
#>
#> $Species
#> [1] "paperclip"
#>
#> $`Approx date of death`
#> [1] "2007-01-01 UTC"
#>
#> $`Weight in grams`
#> [1] 0.9
sapply(clippy$value, class)
#> [[1]]
#> [1] "character"
#>
#> [[2]]
#> [1] "character"
#>
#> [[3]]
#> [1] "POSIXct" "POSIXt"
#>
#> [[4]]
#> [1] "numeric"Final note: all datetimes are imported as having the UTC timezone, because, mercifully, Excel has no notion of timezones.
When column guessing goes wrong
It’s pretty common to expect a column to import as, say, numeric or datetime. And to then be sad when it imports as character instead. Two main causes:
Contamination by embedded missing or bad data of incompatible
type. Example: missing data entered as ?? in a
numeric column.
- Fix: use the
naargument ofread_excel()to describe all possible forms for missing data. This should prevent such cells from influencing type guessing and cause them to import asNAof the appropriate type.
Contamination of the data rectangle by leading or trailing non-data rows. Example: the sheet contains a few lines of explanatory prose before the data table begins.
- Fix: specify the target rectangle. Use
skipandn_maxto provide a minimum number of rows to skip and a maximum number of data rows to read, respectively. Or use the more powerfulrangeargument to describe the cell rectangle in various ways. See the examples forread_excel()help orvignette("sheet-geometry")for more detail.
The deaths.xlsx sheet demonstrates this perfectly.
Here’s how it imports if we don’t specify range as we did
above:
deaths <- read_excel(readxl_example("deaths.xlsx"))
#> New names:
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
#> • `` -> `...5`
#> • `` -> `...6`
print(deaths, n = Inf)
#> # A tibble: 18 × 6
#> `Lots of people` ...2 ...3 ...4 ...5 ...6
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 simply cannot resist writing NA NA NA NA some…
#> 2 at the top NA of thei…
#> 3 or merging NA NA NA cells
#> 4 Name Profession Age Has … Date… Date…
#> 5 David Bowie musician 69 TRUE 17175 42379
#> 6 Carrie Fisher actor 60 TRUE 20749 42731
#> 7 Chuck Berry musician 90 TRUE 9788 42812
#> 8 Bill Paxton actor 61 TRUE 20226 42791
#> 9 Prince musician 57 TRUE 21343 42481
#> 10 Alan Rickman actor 69 FALSE 16854 42383
#> 11 Florence Henderson actor 82 TRUE 12464 42698
#> 12 Harper Lee author 89 FALSE 9615 42419
#> 13 Zsa Zsa Gábor actor 99 TRUE 6247 42722
#> 14 George Michael musician 53 FALSE 23187 42729
#> 15 Some NA NA NA NA NA
#> 16 NA also like to w… NA NA NA NA
#> 17 NA NA at t… bott… NA NA
#> 18 NA NA NA NA NA too!Non-data rows above and below the main data rectangle are causing all the columns to import as character.
If your column typing problem can’t be solved by specifying
na or the data rectangle, request the "list"
column type and handle missing data and coercion after import.
Peek at column names
Sometimes you aren’t completely sure of column count or order, and
yet you need to provide some information via
col_types. For example, you might know that the column
named “foofy” should be text, but you’re not sure where it appears. Or
maybe you want to ensure that lots of empty cells at the top of “foofy”
don’t cause it to be guessed as logical.
Here’s an efficient trick to get the column names, so you can
programmatically build the col_types vector you need for
your main reading of the Excel file. Let’s imagine I want to force the
columns whose names include “Petal” to be text, but leave everything
else to be guessed.
(nms <- names(read_excel(readxl_example("datasets.xlsx"), n_max = 0)))
#> [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am"
#> [10] "gear" "carb"
(ct <- ifelse(grepl("^Petal", nms), "text", "guess"))
#> [1] "guess" "guess" "guess" "guess" "guess" "guess" "guess" "guess"
#> [9] "guess" "guess" "guess"
read_excel(readxl_example("datasets.xlsx"), col_types = ct)
#> # A tibble: 32 × 11
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
#> 2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
#> 3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
#> 4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
#> # ℹ 28 more rowsSquare pegs in round holes
You can force a column to have a specific type via
col_types. So what happens to cells of another type? They
will either be coerced to the requested type or to an NA of
appropriate type.
For each column type, below we present a screen shot of a sheet from
the built-in example type-me.xlsx. We force the first
column to have a specific type and the second column explains what is in
the first. You’ll see how mismatches between cell type and column type
are resolved.
Logical column
A numeric cell is coerced to FALSE if it is zero and
TRUE otherwise. A date cell becomes NA. Just
like in R, the strings “T”, “TRUE”, “True”, and “true” are regarded as
TRUE and “F”, “FALSE”, “False”, “false” as
FALSE. Other strings import as NA.
df <- read_excel(readxl_example("type-me.xlsx"), sheet = "logical_coercion",
col_types = c("logical", "text"))
#> Warning: Expecting logical in A5 / R5C1: got a date
#> Warning: Expecting logical in A8 / R8C1: got 'cabbage'
print(df, n = Inf)
#> # A tibble: 10 × 2
#> `maybe boolean?` description
#> <lgl> <chr>
#> 1 NA "empty"
#> 2 FALSE "0 (numeric)"
#> 3 TRUE "1 (numeric)"
#> 4 NA "datetime"
#> 5 TRUE "boolean true"
#> 6 FALSE "boolean false"
#> 7 NA "\"cabbage\""
#> 8 TRUE "the string \"true\""
#> 9 FALSE "the letter \"F\""
#> 10 FALSE "\"False\" preceded by single quote"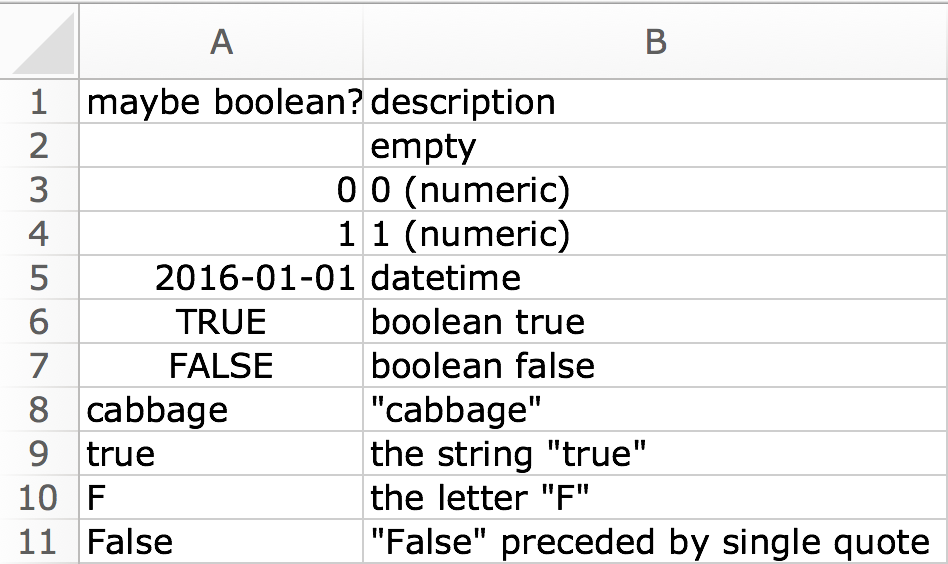
Numeric column
A boolean cell is coerced to zero if FALSE and one if
TRUE. A datetime comes in as the underlying serial date,
which is the number of days, possibly fractional, since the date
origin. For text, numeric conversion is attempted, to handle the
“number as text” phenomenon. If unsuccessful, text cells import as
NA.
df <- read_excel(readxl_example("type-me.xlsx"), sheet = "numeric_coercion",
col_types = c("numeric", "text"))
#> Warning: Coercing boolean to numeric in A3 / R3C1
#> Warning: Coercing boolean to numeric in A4 / R4C1
#> Warning: Expecting numeric in A5 / R5C1: got a date
#> Warning: Coercing text to numeric in A6 / R6C1: '123456'
#> Warning: Expecting numeric in A8 / R8C1: got 'cabbage'
print(df, n = Inf)
#> # A tibble: 7 × 2
#> `maybe numeric?` explanation
#> <dbl> <chr>
#> 1 NA "empty"
#> 2 1 "boolean true"
#> 3 0 "boolean false"
#> 4 40534 "datetime"
#> 5 123456 "the string \"123456\""
#> 6 123456 "the number 123456"
#> 7 NA "\"cabbage\""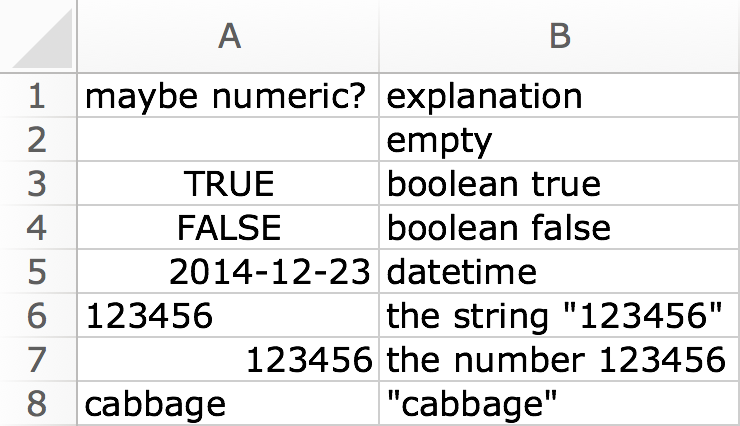
Date column
A numeric cell is interpreted as a serial date (I’m questioning
whether this is wise, but https://github.com/tidyverse/readxl/issues/266).
Boolean or text cells become NA.
df <- read_excel(readxl_example("type-me.xlsx"), sheet = "date_coercion",
col_types = c("date", "text"))
#> Warning: Expecting date in A5 / R5C1: got boolean
#> Warning: Expecting date in A6 / R6C1: got 'cabbage'
#> Warning: Coercing numeric to date in A7 / R7C1
#> Warning: Coercing numeric to date in A8 / R8C1
print(df, n = Inf)
#> # A tibble: 7 × 2
#> `maybe a datetime?` explanation
#> <dttm> <chr>
#> 1 NA "empty"
#> 2 2016-05-23 00:00:00 "date only format"
#> 3 2016-04-28 11:30:00 "date and time format"
#> 4 NA "boolean true"
#> 5 NA "\"cabbage\""
#> 6 1904-01-05 07:12:00 "4.3 (numeric)"
#> 7 2012-01-02 00:00:00 "another numeric"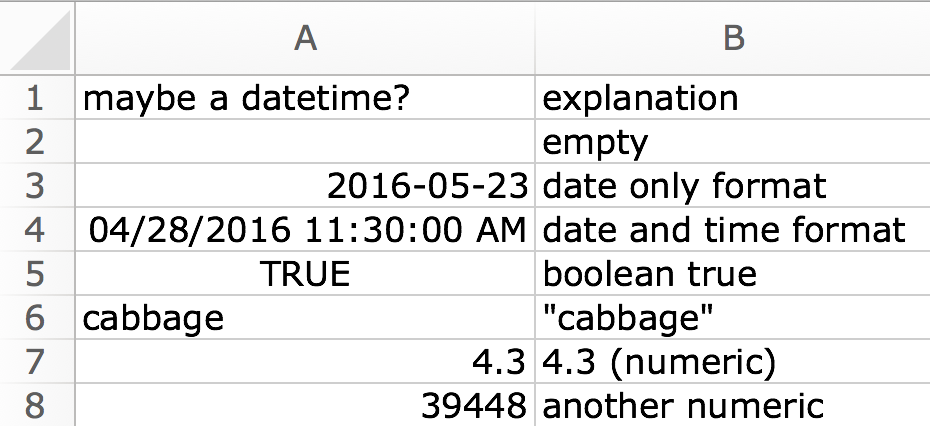
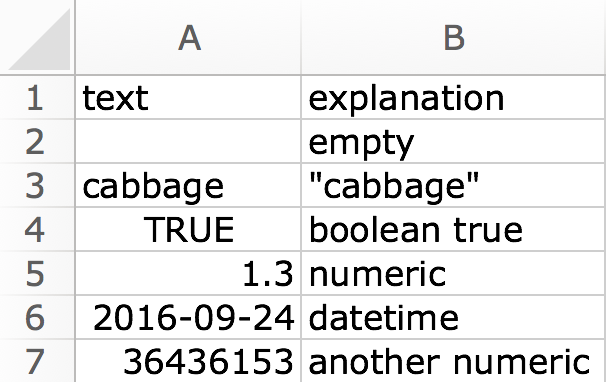
Text or character column
A boolean cell becomes either "TRUE" or
"FALSE". A numeric cell is converted to character, much
like as.character() in R. A date cell is handled like
numeric, using the underlying serial value.
df <- read_excel(readxl_example("type-me.xlsx"), sheet = "text_coercion",
col_types = c("text", "text"))
print(df, n = Inf)
#> # A tibble: 6 × 2
#> text explanation
#> <chr> <chr>
#> 1 NA "empty"
#> 2 cabbage "\"cabbage\""
#> 3 TRUE "boolean true"
#> 4 1.3 "numeric"
#> 5 41175 "datetime"
#> 6 36436153 "another numeric"